
Las imágenes detalladas y rápidas de objetos ocultos podrían ayudar a los automóviles autónomos a detectar peligros. Los investigadores han aprovechado el poder de un tipo de inteligencia artificial conocida como Deep Learning para crear un nuevo sistema basado en láser que puede obtener imágenes ocultas las esquinas en tiempo real.
Con un mayor desarrollo, el sistema podría permitir que los automóviles autónomos «vean» alrededor de automóviles estacionados o intersecciones concurridas para ver peligros o peatones. También podría instalarse en satélites y naves espaciales para tareas como capturar imágenes dentro de una cueva en un asteroide.
«En comparación con otros enfoques, nuestro sistema de imágenes sin línea de visión proporciona resoluciones y velocidades de imagen únicas», dijo el líder del equipo de investigación Christopher A. Metzler, de la Universidad de Stanford y la Universidad de Rice. «Estos atributos permiten aplicaciones que de otro modo no serían posibles, como leer la matrícula de un automóvil oculto mientras conduce o leer un distintivo usado por alguien que camina al otro lado de una esquina».
El diario de The Optical Society para investigaciones de alto nivel, Metzler y sus colegas de la Universidad de Princeton, la Universidad Metodista del Sur y la Universidad de Rice informan que el nuevo sistema puede distinguir detalles submilimétricos de un objeto oculto a 1 metro de distancia. El sistema está diseñado para obtener imágenes de objetos pequeños a resoluciones muy altas, pero se puede combinar con otros sistemas de imágenes que producen reconstrucciones de baja resolución del tamaño de una sala.
«Las imágenes sin línea de visión tienen importantes aplicaciones en imágenes médicas, navegación, robótica y defensa», dijo el coautor Felix Heide de la Universidad de Princeton. «Nuestro trabajo da un paso para permitir su uso en una variedad de tales aplicaciones».
Credit: Prasanna Rangarajan, Southern Methodist University
Resolver un problema de óptica con Deep Learning
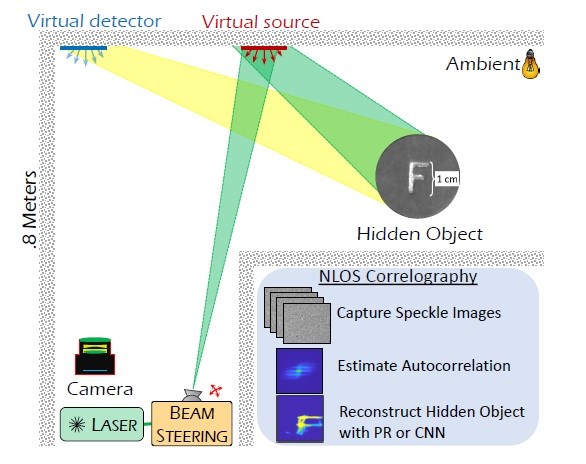
El nuevo sistema de imágenes utiliza un sensor de cámara disponible comercialmente y una fuente láser potente, pero por lo demás estándar, similar a la que se encuentra en un puntero láser. El rayo láser rebota de una pared visible sobre el objeto oculto y luego vuelve a la pared, creando un patrón de interferencia conocido como patrón de manchas que codifica la forma del objeto oculto.
Reconstruir el objeto oculto a partir del patrón moteado requiere resolver un problema computacional desafiante. Los tiempos de exposición cortos son necesarios para obtener imágenes en tiempo real, pero producen demasiado ruido para que funcionen los algoritmos existentes. Para resolver este problema, los investigadores recurrieron al aprendizaje profundo.
«En comparación con otros enfoques para imágenes sin línea de visión, nuestro algoritmo de aprendizaje profundo es mucho más robusto al ruido y, por lo tanto, puede operar con tiempos de exposición mucho más cortos», dijo la coautora Prasanna Rangarajan, de la Universidad Metodista del Sur. «Al caracterizar con precisión el ruido, pudimos sintetizar datos para entrenar el algoritmo para resolver el problema de reconstrucción mediante el aprendizaje profundo sin tener que capturar costosos datos de entrenamiento experimental».
Viendo detrás de las esquinas
Los investigadores probaron la nueva técnica reconstruyendo imágenes de letras y números de 1 centímetro de alto escondidos detrás de una esquina usando una configuración de imágenes a aproximadamente 1 metro de la pared. Utilizando una longitud de exposición de un cuarto de segundo, el enfoque produjo reconstrucciones con una resolución de 300 micras.
La investigación es parte del programa Mejora revolucionaria de la visibilidad de DARPA mediante la explotación de los campos de luz activa (REVEAL), que está desarrollando una variedad de técnicas diferentes para obtener imágenes de objetos ocultos en las esquinas. Los investigadores ahora están trabajando para hacer que el sistema sea práctico para más aplicaciones al extender el campo de visión para que pueda reconstruir objetos más grandes.
Autores: CA Metzler, F. Heide, P. Rangarajan, M. Madabhushi Balaji, A. Viswanath, A. Veeraraghavan y RG Baraniuk, «Correlografía profunda inversa: hacia imágenes de alta resolución sin línea de visión en tiempo real, ”7 (1) 63-71 (2020).
